


Introduction
In this article, we will be using Fashion Product Images Dataset from Kaggle. We all know that Machine Learning is of three prominent methods:
Supervised Learning
Unsupervised Learning
Reinforcement Learning
Supervised Learning
Input data is provided to the model along with the output.
Unsupervised Learning
In unsupervised learning, only input data is provided to the model.
Reinforcement Learning
Reinforcement learning is a machine learning training method based on rewarding desired behaviors and/or punishing undesired ones
Now, this article is entirely based on the first two methods. The motive of this blog is to understand how to use the best of both worlds which is termed as semi-supervised learning.
Semi-Supervised Learning
Semi-Supervised machine learning is a combination of supervised and unsupervised machine learning methods.
Index
Problem Statement
Solution
Dataset Description
Importing Libraries
Initialize Variables
Extract Image Names
Transfer Learning (VGG16)
Preprocess & Extract Features
Read Features
Read CSV
Principal Component Analysis - Feature Reduction
Label Data
Classification
Import Data
Modelling
Conclusion
Author
1. Problem Statement
Consider a scenario in which the task is to build a binary image classification system on the Simpsons (Homer and Bart images). So as a Data scientist you are provided with those images and was expected to build a classification model.
Refer this article (if you are interested): Why CNN is preferred for Image Data that compares ANN, ANN + Feature extraction, CNN to build a binary classification model for Homer-Bart image dataset.
Back to the scenario, consider the data provided to you was labelled, which in our case, Homer images are provided in a separate directory and Bart images are provided in another separate directory so all images from a directory belongs to either Homer or Bart. So that your main focus is on modelling and not on labelling the data since it has been already labelled.
On the other hand, what if the dataset provided to you is un-labelled. That is, you are only provided with a single directory that consists of both Homer and Bart images and to stress you out, there are around 50,000 images or even more images. So before modelling, your task should be labelling and labelling 50,000 images manually is gonna make you hate your life.....😂😂.
So the question is.... What can be done to ease your work?
2. Solution
The answer is.... Use the best of both worlds !!!!
Yes, it is obvious that for classification, supervised learning algorithms are to be used. But since the data is un-labelled, unsupervised learning algorithms such as clustering techniques can be used to label the data first and then classification models can be built on the labelled data.
Let us dive into the implementation in the following sections..
3. Dataset Description
Dataset Link: Fashion Product Images Dataset
A CSV file is provided with the dataset that contains image descriptions based on the file names. Yes, the CSV file can itself be used for labelling the images according to different classes, but since the motive of this article is to understand and implement semi-supervised learning, let's not use the CSV for labelling the images.
4. Importing Libraries
First of all, let's import the necessary libraries for our implementation.
Below are the libraries required for the first task which is labelling the data.
# for loading/processing the images
from keras.preprocessing.image import img_to_array, load_img
from keras.applications.vgg16 import preprocess_input #preprocessing method for VGG16 compatibility
# models
from keras.applications.vgg16 import VGG16
from keras.models import Model
# clustering and dimension reduction
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
import os
import numpy as np
import matplotlib.pyplot as plt
from random import randint
import pandas as pd
import pickle
import shutil
Let's use the VGG16 model (Transfer Learning) for our task. Also, Let's use KMeans clustering for labelling of the images and Principal Component Analysis can be used for feature reduction.
The reason for considering feature reduction technique (un-supervised approach) is because the entire dataset is around 25GB and processing such dense data is time consuming and resource consuming.
Below are the libraries required for the classification task
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Dense,Conv2D,Flatten,MaxPool2D,Dropout
import wandb
from wandb.keras import WandbCallback
We'll use the Weights & Biases tool for logging purposes. And since Keras has compatibility with WandB we'll import WandbCallback as well.
5. Initialize Variables
#clustering variables
#feature extraction by using VGG16 is done once and stored as pickle file
# true - to extract features by using VGG16 and save it as pickle file
# false - to skip the feature extraction and load the pickle file
use_VGG16 = True
Let's define a variable use_VGG16 to denote whether to use transfer learning or not. Since VGG16 will be used to extract features and the extracted features are stored as pickle format (we will be diving into this in the upcoming sections... Don't worry for now), which is a one time task.
During training we are required to run the script multiple times and since feature extraction by VGG16 is a one time task and yes it is time consuming, we'll initialize the variable False to skip the feature extraction step every time other than the first time during which the stored pickle file containing feature vectors are just loaded instead of extracting the features repeatedly. To summarize,
use_VGG16 = True=> VGG16 is used during the first run only to extract features from images and the extracted features are stored in a pickle format.use_VGG16 = False=> Feature extraction by VGG16 is skipped and the pickle file generated before is just loaded.#classification variables target_size = (75,75) batch_size = 32 train_val_split = 0.2 num_classes = 45 nb_epochs = 1000 init_epoch = 29 wandb_resume_state = True exp_name = 'semi_super'num_classes = 45- The image data we have from the Kaggle repository consists of 45 classes. Yes, this information was extracted from the csv file provided in the repository. Since to implement KMeans clustering, K value should be known before-hand and that is why the Csv file is used to extract this information. We'll see how this information was extracted from the Csv as well in upcoming sections.wandb_resume_state= True=> this parameter is passed as argument while training to denote that the model should start the training from the previously arrived best weights. Again, let's see this in upcoming sections.exp_name: this parameter is the experiment id which is passed to the wandb to identify the project in the wandb website.
6. Extract Image Names
files_path = '../input/fashion-product-images-dataset/fashion-dataset/images/'
file_names = os.listdir(files_path)
for i in range(len(file_names)):
file_names[i] = files_path+file_names[i]
#file_names
The above code snippet read each file names in the data directory and stores the path in a list.
7. Transfer Learning (VGG16)
We'll use the VGG16 architecture for feature extraction. Since the VGG16 architecture is used here only to harness its feature extraction capability and not for what it is trained for, let's remove the last two layers of the VGG16 architecture so that the pruned architecture outputs extracted features maps for the input images rather than the classification task for which the architecture was originally implemented for.
The pruned VGG16 (i.e., after removing the last two layers) outputs a vector of 4096 numbers which is the feature map extracted.
model = VGG16() model = Model(inputs=model.inputs, outputs=model.layers[-2].output)8. Preprocess & Extract Features
Additionally, input data for the modified VGG16 is to be preprocessed for compatibility.
VGG model expects the images to be preprocessed as per the function
preprocess_input()from the librarykeras.applications.vgg16preprocess_input() receives inputs as 224x224 NumPy arrays in the format
(num_of_samples, rows, columns, channels).
The function snippet below reads image file received as argument and resize it to (224, 224) and convert it into numpy representation. Then it is reshaped into (1, 224, 224, 3) since the preprocess_input() method requires the data in such format. Then the output from the function is passed to the modified VGG16 architecture which returns feature map consisting of 2096 values.
def preprocess_extract_features(file): img = load_img(file, target_size=(224,224))#load image and resize into 224x224 (for VGG16 preprocess compatibility) img = np.array(img) #print(img.shape) #(rows,columns,channels) reshaped_img = img.reshape(1,224,224,3) #print(reshaped_img.shape) #(num_of_samples, rows, columns, channels) img = preprocess_input(reshaped_img)#preprocess images for VGG16 model features = model.predict(img) #predict (since last two layers are dropped, gives feature-maps / features) return featuresLet's create a dictionary with file name as key and feature as values for each image data.
features_dict = dict()
if use_VGG16: #run only if feature extraction is to be done now (else load the features from pickle file)
for i in file_names:
file = i.split('/')[-1].split('.')[0]
features_dict[file] = preprocess_extract_features(i)
The extracted feature vectors of images are stored as pickle format only during the run in which feature extraction is to be done which is indicated by the variable use_VGG16=True
if use_VGG16:
#save the dictionary of features as pickle only if feature extraction is done now
with open('features.pkl','wb') as file:
pickle.dump(features_dict, file)
9. Read Features
If the features are already extracted and it is only to be loaded during this run, the below snippet does this task.
if not use_VGG16:
#load saved feature dictionary if already pickle file is saved
with open('../input/fashion-features/features_large.pkl','rb') as f:
data = pickle.load(f)
#extract filename and features from the dictionary
filenames = np.array(list(data.keys()))
features = np.array(list(data.values())).reshape(-1,4096)
features.shape
10. Read CSV
Now to summarize what we have done so far, features are extracted using the VGG16 architecture after modifying the architecture and the features are stored as pickle format for future use instead of doing it again and again for each run.
Now, we have to cluster the images according to 45 classes since the images are of 45 categories. But how did we arrive at this number??? Yes, it is from the Csv file. Let's see how we arrived at this number.
df = pd.read_csv('../input/fashion-product-images-dataset/fashion-dataset/styles.csv', on_bad_lines='skip')
df[['masterCategory', 'subCategory', 'articleType']].nunique() #categories in dataset
label = df['subCategory'].tolist() # cluster based on subcategory (45 subcategories)
unique_labels = list(set(label))
print(len(unique_labels))
45 subCategories are present in the entire dataset.
11. Principal Component Analysis - Feature Reduction
Now we have the extracted features which is of 2096 numbers for each image. Such huge dataset with 2096 numbers as features for each image is gonna consume a lot of resource. Therefore, it is good to reduce the features. We'll use Principal Component Analysis (an un-supervised technique approach) to reduce the features from 2096 to 1000 for each image.
pca = PCA(n_components=1000, random_state=22)#reduce to 1000 dimensions
pca.fit(features) #fit
x = pca.transform(features) #transform
12. Label Data
Now after feature extraction and feature reduction, let's label the images based on 45 classes. But how to label image data? We'll just create folders for 45 classes and move the original images to the folders based on the clustered classes.
kmeans = KMeans(n_clusters=len(unique_labels), random_state=22) #cluster image data into 45 groups
kmeans.fit(x)
#create dictionary with filepath and labels assigned by KMeans
groups = {}
for file, cluster in zip(filenames,kmeans.labels_):
if cluster not in groups.keys():
groups[cluster] = []
groups[cluster].append(files_path+file)
else:
groups[cluster].append(files_path+file)
The above snippet creates a dictionary with key as filename and value as cluster label assigned by the KMeans.
Now, let's move the original images to the folders.
os.mkdir('./Clustered Data')
for i in groups.items():
os.mkdir('./Clustered Data/' + str(i[0]))
for j in i[1]:
shutil.copy(j+".jpg", "./Clustered Data/" + str(i[0]) + "/" + j.split('/')[-1] + ".jpg")
Now, labeling of the image data is done i.e, the un-supervised part is over. Then comes the supervised part where the aim is to create a multiclass classification model to classify the 45 classes.
13. Classification
Configurations for WandB are,
wandb.login(key='5246287025871fb44919b66f47f36cbe454c16a5')
if wandb_resume_state:
wandb.init(project="Fashion-Semi-Supervised", resume=True, group=exp_name)
else:
exp_name = wandb.util.generate_id()
myrun = wandb.init(
project='Fashion-Semi-Supervised',
group=exp_name,
config={
'Image Size':75,
'Num Channels':3,
'Epoch': nb_epochs,
'Batch_size':batch_size,
'Loss':"categorical_crossentropy",
'Optimizer':'Adam',
}
)
config = wandb.config
5246287025871fb44919b66f47f36cbe454c16a5 is the API key provided for each account by Wandb. The above snippet, when wandb_resume_state=True, considers the same parameters. When wandb_resume_state=False, it initializes the parameters from scratch.
14. Import Data
Let's import the data we labelled using ImageDataGenerator.
train_data_gen = ImageDataGenerator(rescale=1./255, validation_split=train_val_split)
train_generator = train_data_gen.flow_from_directory(
directory='./Clustered Data/',
target_size = target_size,
batch_size = batch_size,
#color_mode='grayscale',
class_mode = 'categorical',
subset='training')
validation_generator = train_data_gen.flow_from_directory(
directory='./Clustered Data/',
target_size = target_size,
batch_size = batch_size,
#color_mode='grayscale',
class_mode = 'categorical',
subset='validation')
labels = list(train_generator.class_indices.keys())
15. Modelling
The below snippet describes the model building. If training is to be resumes, the best model is loaded else model is built.
if wandb.run.resumed: #if run is to be resumed
model = keras.models.load_model(wandb.restore("model-best.h5").name)
else:#else new run
model= Sequential()
model.add(Conv2D(kernel_size=(3,3), filters=32, activation='tanh', input_shape=(75,75,3)))
model.add(Conv2D(filters=30,kernel_size = (3,3),activation='tanh'))
model.add(MaxPool2D(2,2))
model.add(Conv2D(filters=30,kernel_size = (3,3),activation='tanh'))
model.add(MaxPool2D(2,2))
model.add(Conv2D(filters=30,kernel_size = (3,3),activation='tanh'))
model.add(Flatten())
model.add(Dense(20,activation='relu'))
model.add(Dense(15,activation='relu'))
model.add(Dense(num_classes,activation = 'softmax'))
model.compile(loss='categorical_crossentropy', metrics=['acc'], optimizer='adam')
Now, initialize wandb keras compatibility which takes parameters from keras and logs on the site. Refer the official documentation of Wandb-Keras for each parameter description.
#wandb keras compatibility
wandb_call = WandbCallback(save_model=True,
save_graph=True,
save_weights_only=True,
log_weights=True,
log_gradients=True,
training_data=train_generator,
validation_data=validation_generator,
validation_steps = validation_generator.samples // batch_size,
labels=labels,
predictions = 180,
input_type='images')
Now let's, fit the model. Note here, the wandb callback is passed here.
history = model.fit(
train_generator,
initial_epoch=wandb.run.step,
steps_per_epoch = train_generator.samples // batch_size,
validation_data = validation_generator,
validation_steps = validation_generator.samples // batch_size,
epochs = nb_epochs,
callbacks=[wandb_call])
Now, the classification model is built as well.
16. Conclusion
So to summarize, in this article we have seen how to use both supervised and unsupervised learning technique for the Fashion Image Dataset. We have used VGG16 to extract features from the images and those features are reduced in dimensions using Principal Component Analysis (PCA) and then KMeans clustering approach is used to cluster the images based on 45 categories. Then labelling is done based on the clustered data. Then classification model is build on the labeled data.
So, semi-supervised learning technique combines both supervised and unsupervised technique to achieve the task we considered here. The task in our case is to label the data and to build a multi-class classification model.
Please go through Wandb documentation to understand the wandb code.
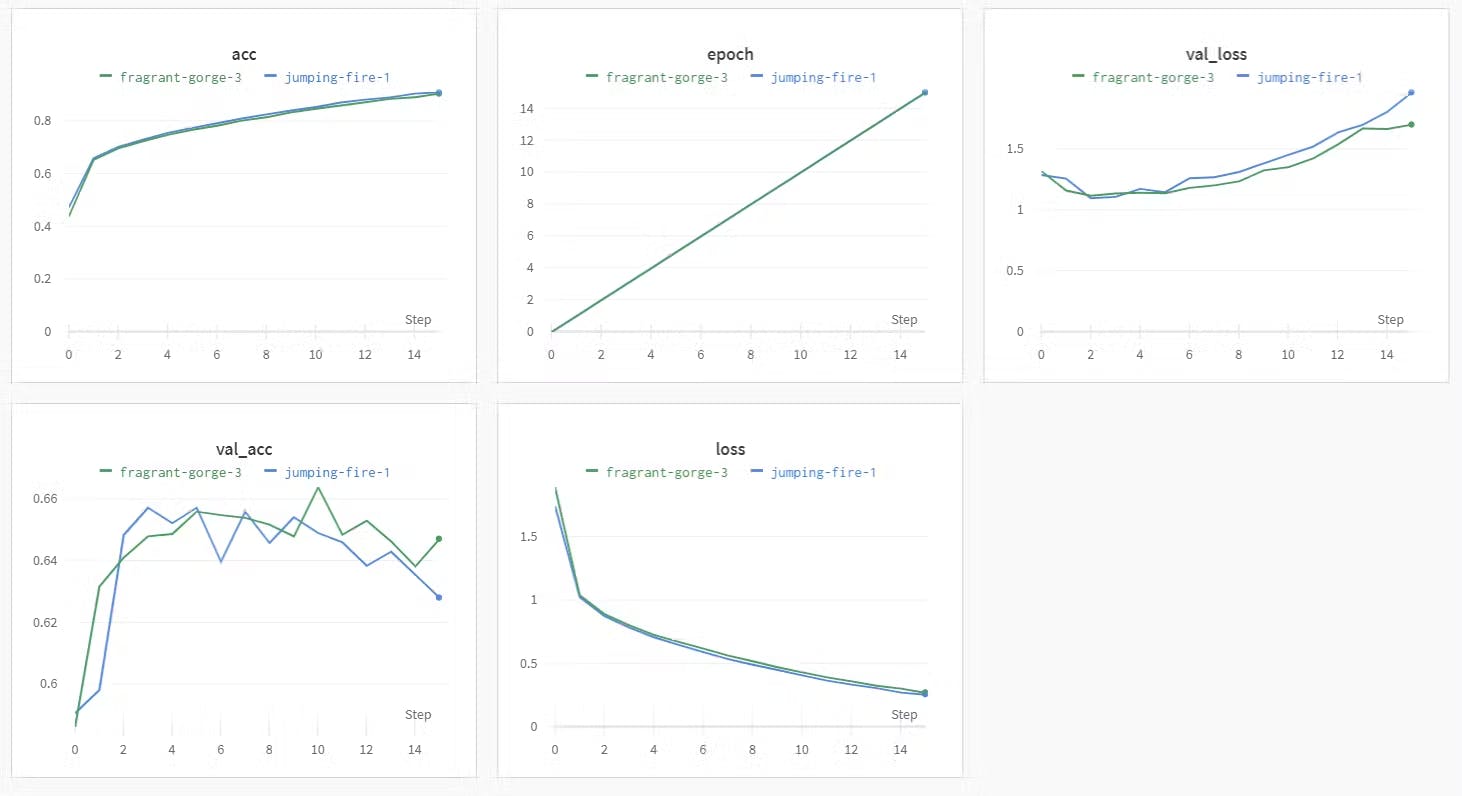
The output can be seen here in the wandb project : Fashion-Semi-Supervised
Screenshot from the Wandb website:
17. Author
You can find the code on my Github : Clustering-Classification-Fashion Dataset
About the Author :
Hiii, I'm Avinash, pursuing a Bachelor of Engineering in Computer Science and Engineering from Mepco Schlenk Engineering College, Sivakasi. I'm an AI enthusiast and Open-Source contributor.
Connect me through :
Feel free to correct me !! :)
Thank you folks for reading. Happy Learning !!! 😊